Data Processing
1. Introduction
For any company, data has become the most important tool for making critical decisions. Data processing occurs when data is collected and translated into usable information. Technological intervention has helped to increase the credibility of data analysis. Newer technologies, such as machine learning, are highly dependent on bulk data. It is important for data processing to be done correctly as not to negatively affect the end product, or data output.
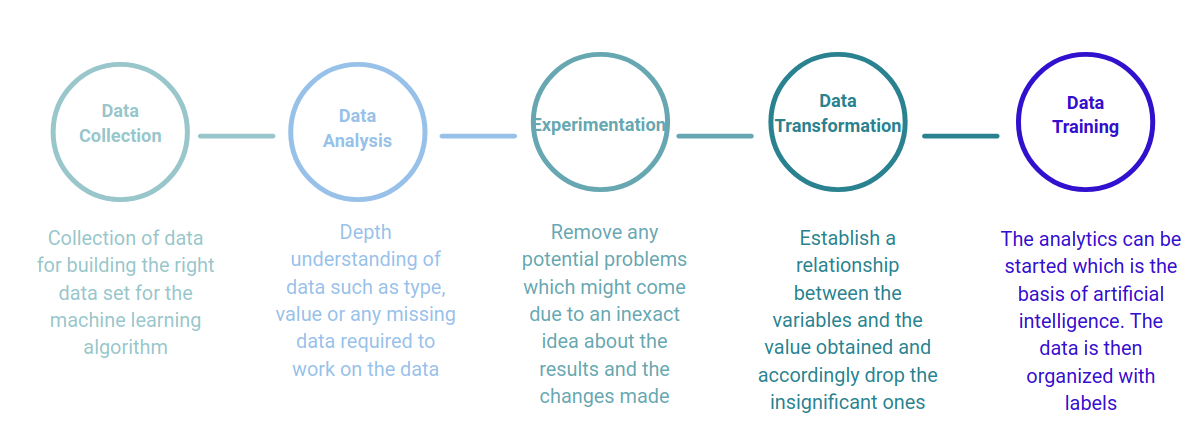
Data processing starts with data in its raw form and converts it into a more readable format (graphs, documents, etc.), giving it the form and context necessary to be interpreted by computers and utilized by employees throughout an organization. The organization must then understand the concept of analysis and must spend time collecting the data, cleaning it, exploring it, and modifying it in the required format.
For those working with machine learning and other advanced technologies, there is a hierarchy that must be followed in the processing of data:
2. Machine Learning
2.1. Definition
Machine learning is a field of study of artificial intelligence(AI) that uses mathematical and statistical approaches to give computers the ability to "learn" from data, i.e. to improve their performance in solving tasks without being explicitly programmed for each one. More broadly, it concerns the design, analysis, optimization, development, and implementation of such methods.
These methods include: Random forest (RF) and Neural networks (NN).
Machine learning generally involves two phases :
-
Model estimation : from data, called observations, which are available in finite numbers during the system design phase. Model estimation consists of solving a practical task, such as translating a speech, estimating a probability density, or recognizing the presence of a cat in a photograph. This so-called "learning" or "training" phase is usually carried out prior to the practical use of the model.
-
Putting into production : once the model has been determined, new data can then be submitted in order to obtain the result corresponding to the desired task. In practice, some systems can continue their learning once in production, provided they have a means of obtaining feedback on the quality of the results produced (source: Wikipedia).
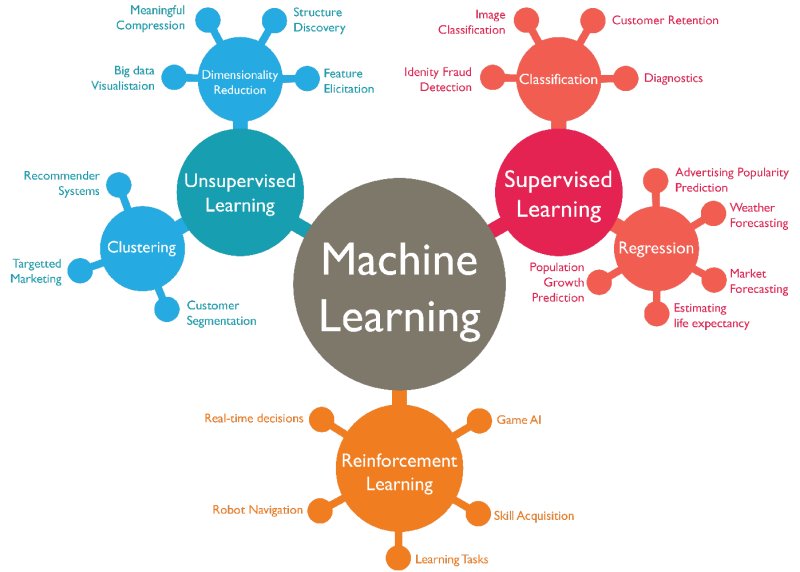
2.2. Machine learning categories
Machine learning techniques are needed to improve the accuracy of predictive models. Depending on the nature of the business problem being addressed, there are different approaches that vary according to the type and volume of data :
-
Supervised learning : the goal of supervised learning is to identify patterns in the data and apply them to an analytical process. These data have features associated with labels that define their meaning. For example, create a machine learning application capable of distinguishing between several million animals, based on images and written descriptions.
-
Unsupervised learning : it is used when the problem requires a massive amount of untagged data and conducts an iterative process, analyzing data without human intervention. For example, social networking applications such as Twitter exploit very large amounts of untagged data. To understand the meaning of this data, it is necessary to use algorithms that classify the data according to the trends or clusters they detect.
-
Reinforcement learning : it is a model of behavioural learning. The algorithm receives feedback from the data analysis and guides the user to the best result. The system learns through a trial and error method.
3. Deep Learning
3.1. Definition
Deep learning is a type of artificial intelligence derived from machine learning, which is based on computers processing large amounts of data using artificial neural networks based on the human brain. Whenever new information is integrated, the existing connections between neurons can be modified and extended, allowing the system to learn without human intervention, autonomously, while improving the quality of its decision-making and forecasting.
Deep Learning is used in many areas: image recognition, machine translation, autonomous car, medical diagnosis, financial prediction, automated trading, and intelligent robots.
3.2. How Deep Learning Works
Artificial neural networks, consisting of an input layer of neurons, one or more intermediate layers, and an output layer, are used to process information. The incoming information, or input vector, reaches the input layer; it is then transmitted by the artificial neurons to the intermediate layers, where it is given a "weight"; and finally, it adopts a certain pattern when it reaches the output layer.
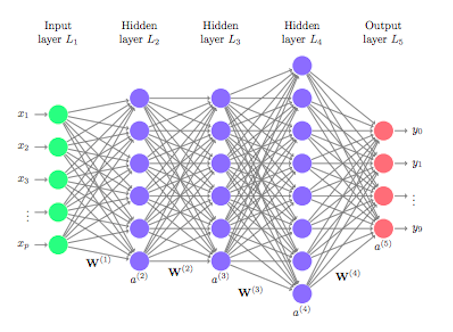
The system will, for example, learn to recognize letters before attacking words in a text or determine whether there is a face in a photo before finding out which person it is.
At each step, "wrong" answers are eliminated and sent back to the upstream levels to adjust the mathematical model. As you go along, the program reorganizes the information into more complex blocks. The more different experiences the system accumulates, the better it will perform (the more layers an artificial neural network contains, the more complex tasks the AI can undertake).